Relational AI
Computer system software, like operating systems, database management systems, or video game engines, has traditionally been implemented in low-level programming languages like C or C++. There are good reasons for this: among them, systems programmers must routinely cope with resource constraints dictating low-level control over memory layouts and memory management. Such concerns are some of the very ones that productivity languages like Julia seek to hide from view.
For example, consider the venerable B+-tree, which has been used for decades in database systems, file systems, and elsewhere. A B+-tree is a tree-structured index (over, say, file system metadata or SQL tables) aiming to minimize disk I/O for datasets too large to fit in main memory. It achieves this by using large nodes, sized to some multiple of operating system pages, with wide fanout. Because nodes are so wide, the tree is very shallow, and searching from root to leaf incurs just a few disk I/Os. Here’s a picture from Wikipedia (in a real B+-tree, the nodes would contain thousands of entries each and have more intricate internal structure):
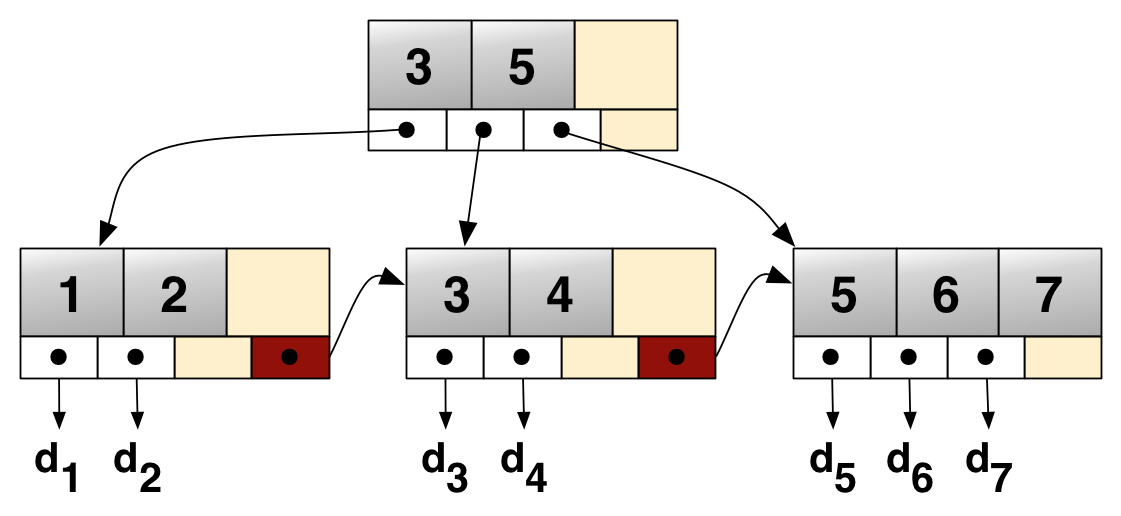 B+-tree In a student project, B+-trees could be implemented in a straightforward way, with e.g. search through a node done by deserializing the page’s contents into appropriate heap-allocated data structures in the host language, and then working with those data structures. In a real implementation, however, this is considered unacceptably slow and resource-intensive; instead the page itself is simply “cast” to a C/C++ data structure, for example, and worked with directly. Systems languages are distinguished by their capability to support this style of programming.
At the same time, systems programmers are painfully aware of the productivity limitations of languages like C/C++, and recurrent attempts have been made over the years in nearly every systems context to experiment with the use of higher-level languages. Indeed, the most famous and successful example of this is C itself, which replaced assembly language as the “high-level” systems alternative of its time.
Recently, in database systems, the use of query compilation (on-the-fly compilation of ad-hoc SQL queries into machine code) has become more or less ubiquitous in high-performance systems. The pain of implementing query compilation in a traditional systems language like C/C++ has motivated researchers to explore the use of higher-level languages like Scala, equipped with staged code generation libraries like LMS or Squid, in order to build high-performance systems prototypes.
In such a context, Julia presents an intriguing alternative, due to its excellent performance and well-developed staged metaprogramming facilities. But if we want to build a full-blown database system in Julia, can we also implement low-level data structures like B+-trees in a way that is both idiomatic to Julia (and therefore productive), but also efficient?
In this talk, we answer this question in the affirmative, by showing how such data structures can be implemented with help from a recently-developed package called Blobs package. Blobs (see also ManualMemory) uses Julia metaprogramming techniques to make it easy and efficient to lay out complex data structures within a memory region, such as an OS page. Data structures are defined as ordinary isbits Julia structs, and can have rich nested structure. Rather than give examples here, take a look at the package overview.
We’ll give a quick and self-contained overview of the necessary background on paged data structures, and then show how to use Blobs to implement such data structures natively in Julia.
B+-trees are a bit old-fashioned nowadays, so time allowing, we may also try to cover an example of a more recent paged data structure, the Bε-tree. This data structure allows a precisely tunable tradeoff between read- and write-performance, and has been used recently in advanced database systems (TokuDB, LogicBlox) and file systems (BetrFS).
B+-tree In a student project, B+-trees could be implemented in a straightforward way, with e.g. search through a node done by deserializing the page’s contents into appropriate heap-allocated data structures in the host language, and then working with those data structures. In a real implementation, however, this is considered unacceptably slow and resource-intensive; instead the page itself is simply “cast” to a C/C++ data structure, for example, and worked with directly. Systems languages are distinguished by their capability to support this style of programming.
At the same time, systems programmers are painfully aware of the productivity limitations of languages like C/C++, and recurrent attempts have been made over the years in nearly every systems context to experiment with the use of higher-level languages. Indeed, the most famous and successful example of this is C itself, which replaced assembly language as the “high-level” systems alternative of its time.
Recently, in database systems, the use of query compilation (on-the-fly compilation of ad-hoc SQL queries into machine code) has become more or less ubiquitous in high-performance systems. The pain of implementing query compilation in a traditional systems language like C/C++ has motivated researchers to explore the use of higher-level languages like Scala, equipped with staged code generation libraries like LMS or Squid, in order to build high-performance systems prototypes.
In such a context, Julia presents an intriguing alternative, due to its excellent performance and well-developed staged metaprogramming facilities. But if we want to build a full-blown database system in Julia, can we also implement low-level data structures like B+-trees in a way that is both idiomatic to Julia (and therefore productive), but also efficient?
In this talk, we answer this question in the affirmative, by showing how such data structures can be implemented with help from a recently-developed package called Blobs package. Blobs (see also ManualMemory) uses Julia metaprogramming techniques to make it easy and efficient to lay out complex data structures within a memory region, such as an OS page. Data structures are defined as ordinary isbits Julia structs, and can have rich nested structure. Rather than give examples here, take a look at the package overview.
We’ll give a quick and self-contained overview of the necessary background on paged data structures, and then show how to use Blobs to implement such data structures natively in Julia.
B+-trees are a bit old-fashioned nowadays, so time allowing, we may also try to cover an example of a more recent paged data structure, the Bε-tree. This data structure allows a precisely tunable tradeoff between read- and write-performance, and has been used recently in advanced database systems (TokuDB, LogicBlox) and file systems (BetrFS).
T.J. Green is a Computer Scientist at Relational AI. Previously, he was a Computer Scientist at LogicBlox, and an Assistant Professor at UC Davis. He received his B.S. in Computer Science from Yale University in 1997, his M.S. in Computer Science from the University of Washington in 2001, and his Ph.D. in Computer and Information Science from the University of Pennsylvania in 2009. His awards include Best Student Paper at ICDT 2009, the Morris and Dorothy Rubinoff Award in 2010 (awarded to the outstanding computer science dissertation from the University of Pennsylvania), an honorable mention for the 2011 Jim Gray SIGMOD dissertation award, an NSF CAREER award in 2010, and Best Paper Runner-Up at ICDE 2012. Prior to beginning his Ph.D., he worked at Microsoft as a Software Design Engineer and Development Lead, and at Xyleme as a Software Design Engineer.